锟斤拷是什么?
23 个回答


哈哈哈,感觉LZ要百度一会gbk和utf8是什么,你们都起开让我来。
---------------- 写在开始----------------
首先呢,假设LZ没有计算机知识,我们来了解下什么是编码,编码就是对计算机上的二进制信息的规则的识别,把二进制转化为人可识别的字母汉子符号是decode过程,把人们了解的这些信息转化为二进制存储是encode过程。
计算机程序的存储只有0和1,先不说汉子的表达,先说英文的表示方法
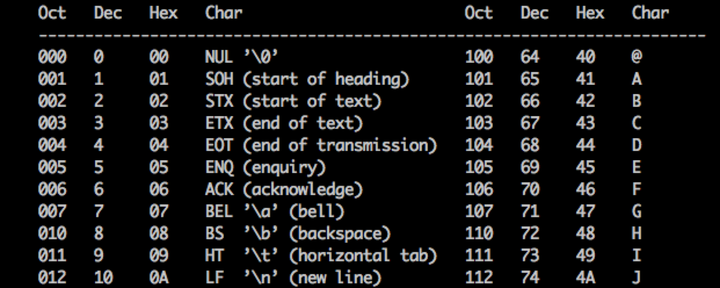

随便在终端man 一下 ascii,截取了一小段,这就是一个二进制到可见字符的对应表。
举个例子:我们看第二行,后面Oct是八进制表示,Dec是十进制,Hex是16进制表示,
“101 65 41 A” 这一栏 就是说 大写字母“A”存储在计算机的一个字节里是 0x41,也就是二进制 "01000001",刚好占据一个字节(8bit),所以你在屏幕上看到的所有的字符“A”,其实在计算机内部都是用一个字节存储的,而内部的值是01000001。
上图的编码是ASCII (American Standard Code for Information Interchange),不是ASC2 ,不过这套编码体系只解决了一些常用字符,控制字符,还有英文和数字等,最大表示的字符数也就只有一个字节(8bit=256)那么多 ,如果要表达中文或者这个星球上所有的其他语言以及表情符号,象形文字乱七八糟的,必须要扩充这个字符集,于是unicode系列就出来。
-------------- UNICODE系列 ----------------
Unicode 或者UCS(the Universal Character Set)是某一国际化组织(懒得百度)制定的可以容纳世界(覆盖人类已有文明)上所有文字和符号的字符编码方案,要想做到这一点,那么unicode的设计必须要足够灵活。
Unicode用数字0-0x10FFFF来映射这些字符,最多可以容纳1114112个字符,或者说有1114112个码位。码位是什么?就是上面说的代表字符“A”的01000001,只不过这个只有一个字节。可以想象这100多万个数字应该足够表达所有的字符了,吧。
为了表达更多的字符,只有8个bit是不够的,于是便扩充了字节数来表示更多的字符,那么便出现了UCS-2和UCS-4,这两者的区别就是,UCS-2用两个字节表示,而UCS-4用四个字节表示,明显后者比前者的表达能力要大,前者只有两个字节,两个字节是能表达多少?2^16= 65535,离unicode的目标0x10FFFF差距不少,但是有一些算法可以满足表达,暂且不说了,而UCS-4的4个字节则完全没问题了,好了这都不是重点。
重点是utf系列,unicode只是定义了一种映射表,也就是说65就是代表字母“A”,但是它怎么存在计算机上自己定。也就是说还有一套转换机制,叫UTF
---------------- UTF系列-----------------
UTF (Unicode Transformation Format)是吧unicode定义的映射表,存储在计算机上的规则,比如 ascii的存储方式就是 0x41,也就是存成01000001。
UTF分为 UTF-16 UTF-32 和UTF-8系列,后面这个数字的含义就是说用几个字节存储了,USC-2对应的就是UTF-16,而USC-4对应的就是UTF-32,前者占两个字节,表达能力弱一点,后者占四个字节表达能力强一点,但是无论前者还是后者,都是固定的用2个字节或者四个字节来表达一个字符,这显然不能忍啊,如果我天天打英文,只用1个字节就搞定了,你非要给我搞那么多故事头子干嘛。
于是UTF-8就出现了,它在表达英文这种字符的时候和ascii码一致(其实也并不完全一致,先不要在意),只需要8个字节就够了,当需要表达更多字符的时候,utf8会自动扩充,假如某个字符需要多于一个字节表示,只看前两位就知道了。
比如:
单字节编码的第一字节为[00-7F]因为字母和常见字符只需要0~128个就可以表示,第一个bit只要不是1,那么这个字符就是单字节的。
双字节编码的第一字节为[C2-DF],当我读下一个字符的时候,发现第一个字节的开头前两个bit是11,那么当前这个字符是双字节的。
三字节编码的第一字节为[E0-EF]。当我读下一个字符,发现第一个字节的开头三个bit是111,那么这个字符就是三字节的。
三字节编码的第一字节为[F0-FF]。当我读下一个字符,发现第一个字节的开头四个bit是1111,那么这个字符就是四字节的
怎么样,是不是没听懂!没听懂也不管了。
----------------GBK系列-----------------
中国人民争强好胜,自己又定义了一套编码,这个编码是和Unicode兼容的,也就是说映射表是一样的,比如汉子“水”的unicode编码是 0x6C34,那么它用utf8表示和用gbk表示,都是这个值,只是存储在计算机上不太一样。所以不了解unicode,只说gbk,utf8什么的完全搞不清楚三者是什么关系。
GBK编码严格用了两个字节来表示字符,因为只给中国人用,只要表达汉子和字母就可以了,两个字节上面说能表达65536个字符,可见足够了,可见中国标准委员会的眼光是多么的浅,他们大概没有遇到过编码转换问题,反正编码转换给现在互联网公司带来的坑太多了。(也不是说一点好处都没有,utf8表达汉子要用3个字节,2个字节的gbk在存储空间上省了一些)
在强调一遍,带来的坑太多了,太多了,太多了!
GBK的编码范围是 0x8140-0xFEFE,详细解刨一下
高位时0x81 ~ 0xFE 也就是 1000 0001 - 11111110
低位时0x40 ~ 0xFE 也就是 0100 0000 - 11111110
但不包括低字节是0x7F的组合。(低字节是0x40-0x7E的组合是导致GBK是一个弱逼的主因,至于为什么,可以观察到, 高字节的第一个bit是1,也就是说和asci的可见字符是不冲突的,而低字节的开头是0,那么不难保证低字节可能出现 01000001 这样的字符,而这个字符恰好是ascii的 A,这不就冲突了么,冲突会导致有些用ascii作为分隔符来存储gbk编码数据的系统出现问题,好,打住)
有了上面的知识,下面我们来人肉编码一下“水”这个字符的utf8编码结构
“水”对应的unicode是 0x6C34 也就是 0110 (6) 1100(C) 0011(3) 0100(4) ,那么咋的一看utf8要用3个字节表示,第一个字节是 1110 xxxx ,第二个字节是 10 xxxxxx, 第三个字节是 10 xxxxxx,我们把 0x6C34的值填充到这三个字节的x里,得到 1110 0110, 10 110000,10 110100,这三个字节就是 0xE6B0B4 ,也就是“水”的UTF8编码了。
好,我们在顺变人肉编码一下水的GBK编码,怎么做呢?没法做...
因为GBK的内码不是连续的,而且和unicode标准没有必然的关系,所以大部分程序在做转换的时候都是依赖的转换表。
--------------- 锟斤拷 ------------------
UNICODE的字符列表有一个特殊的字符,也就是0xFFFD,这个字符的wiki解释是这样的
- U+FFFD � replacement character used to replace an unknown or unrepresentable character
It is used to indicate problems when a system is not able to render a stream of data to a correct symbol. It is most commonly seen when a font does not contain a character, but is also seen when the data is invalid and does not match any character它的用途是说,比如说android系统还没有emoji表情的时候,你用你的iphone给android系统发送了一个emoji表情,那么android的机器就傻了啊,这个该展示成什么样呢?于是这个字符就派上用场了,我把它展示为 � 就行啦!
是的,这个字符的使用很依赖你当时所使用的程序,举个很实际的例子,我在iphone上敲下了字符 "←←" ,这个符号"← ",的utf8编码是 "0xe2 0x86 0x90" ,
对应的 unicode是什么呢,我们换算一下 1110 0010 , 1000, 0110, 1001 0000 ,截取后半部分 , 是 0010 0001, 1001 0000 ,也就是 0x2190 ,这就是这个符号的unicode。
现在我把这个符号发送给一个根本不认识他的低端手机,比如就是安德猴好了,这个手机的编辑器看到这个unicode后不知道该渲染成什么字符,因为它根本不认识,那么它就把0x2190 替换为 0xFFFD,因为根据ucs标准,这个0xFFFD的符号是�,就是用来容错的时候用的。
展示的时候存在手机上的是utf8编码,那么0xFFFD对应的utf8编码是什么呢?我们带入三元组的utf8模版 就是 1110 1111 , 10 111111, 10 11 1101 ,那么这用16进制表示就是 0xEF 0xBF 0xBD
好,下面才是真正的关键,"锟斤拷"是怎么出现的呢,还有一步,这个编辑器转换为 0xFFFD后给你看到了,同时存储在手机上的utf8编码是 0xEFBFBD ,然后这个使用安德猴的人手贱,他原封不动的把看到的信息转发给另一个人,那个人使用的编辑器是用GBK解码的,他并不知道这段字符原始的编码格式是utf8,于是他按照gbk来解码这三个字符,由于我在iphone上输入的是两个箭头,那么这个人接收到的数据应该是两组 0xEFBFBD,也就是 0xEF 0xBF 0xBD 0xEF 0xBF 0xBD ,6个字节,我们按照每两个字节,去查询gbk编码对应的汉子,就会发现刚好对应着这三个汉子
锟(0xEFBF)
斤(0xBDEF)
拷(0xBFBD)于是,只有这第三个人看到的才是 锟斤拷。
所以很多时候这个问题有时候出现,有时候不出现,有时候有可能就是普通的乱码,有些浏览器做的比较好也不会出现,这种情况必须要满足上面列举得三组条件才可以。
1. 大于一个稀有的字符 ,至少俩,不然无法配对
2. 某一编辑器或软体识别不了,并且很有节操的给你替换成了0xFFFD展示
3. 展示后的文本又无节操(有可能这个人就是你)的直接传递给了另一个编辑器,而那个编辑器必须是GBK编码的
以上。


